How to scientifically define Cognitive Complexity ?
Introduction
The cognitive complexity of a code snippet is one of the main parameters affecting the maintainability of a software. An approximative definition of the cognitive complexity could be “the difficulty for a developer to understand a code snippet”. Unfortunately, this definition is too vague to be able to measure it, and there is a lack of scientific consensus of what is precisely the cognitive complexity. This fact implies that many approaching definitions exist, thus many formulas to measure it, and finally different results for the same intuitive notion.
In a previous article, I gave the definition below:
Definition
The cognitive complexity of a code snippet is the time required by a mean developer to understand it.
With this definition, we clearly know what we should measure: a duration. However, there are still a lot of imprecise words: code snippet, mean developer, understand.
The first goal of this article is to provide suggestions of possible scientific definitions of these words, in the aim to eliminate the ambiguities. When this work will be done, we’ll be able to provide a consensual definition of the cognitive complexity, and so what we should measure and how to do it.
The second goal of this article is to elaborate a methodology which could help us to define and rely on the different concepts underlying the intuitive notion of cognitive complexity. This methodology, that I called the graph of concepts, may be a good way to organize our ideas, and state some propositions or conjectures.
The aim of my previous article was to popularize the concept of cognitive complexity, and to discuss the validity of the SonarQube’s algorithm. If it’s the first time that you heard about cognitive complexity, you should read it first.
The measurability
To be able to measure the cognitive complexity, we should at first remember what is a measure. This is the aim of the measurement theory.
In this article written by Cem Kaner in 2004, you will find an excellent discussion on what is a measurement, and what are the questions that we should ask us before we try to measure something. I will not enter in details of the measurement theory, but I think that the definition of the measurement given by this author is interesting:
Definition
Measurement is the empirical, objective assignment of numbers, according to a rule derived from a model or theory, to attributes of objects or events with the intent of describing them.
As you can see, our definition of cognitive complexity is clearly not precise enough to respect this definition of measurement. My work consists to clarify the definition of the cognitive complexity, and the definition of all its underlying concepts.
In this section, I will only talk about the difference between measurability and computability. The aim of this discussion is to clarify the border between the world of measurability, and the world of computability.
Let’s start with a simple example. Assume that you want to measure the length of a steel bar. How will you do that ? At first, you will take a folding rule. Of course, you know that this tool is not perfect. Thus, there is a first approximation of the measure due to the instrument. Then, you’ll perhaps note that the steel bar has a thickness. Consequently, if you want to have a precise measure, you should at first find the centers of the extremities of the bar. But where are they exactly ? When you will find them, you will say: OK, now all is perfect, I just need to measure the exact length of the segment between these two points ! And it’s at this precise moment that you’ll remember that, thanks to Albert Einstein, we know that the shortest way to travel from a point A to a point B is not to take a straight line, but a curve, because of the curvature of space-time. At this moment, you will simply throw the steel bar into the river and come back home.
In the real world, no one physical law is able to perfectly describe the reality, and no one measure instrument is able to give a result with exactitude: we will only have approximations, good or bad. This is true for very intuitive notions, like distance, duration or temperature, and it is even more true for human cognition.
That’s why our first good resolution should be to never say that the result of a given formula is the cognitive complexity: it will only be a good or bad approximation of it.
In my opinion, we should divide our researches in four consecutive steps :
- Define as precisely as possible all the concepts on which the cognitive complexity depends.
- Define how to measure cognitive complexity (experimental protocols, extraction of relevant information from massive data, …).
- Conduct experiments and find some ways to collect massive data in relation with Cognitive Complexity.
- Develop an algorithm which is able to provide results highly correlated with the results of the experiments.
Each step depends on the previous one. For me, it is a waste of time to try to write beautiful formulas before having crossed the 3 first steps.
The graph of concepts
Each concept has a definition which is based on parent concepts. For example, the acceleration is “the derivative of the velocity”. The velocity is (sorry for the simplifications) “the distance divided by the time”. The distance in some Euclidean Space is…, etc. (the Euclidean Spaces are super cool spaces which are not curved, not like the naughty space-time of the General Relativity Theory).
We can represent these imbrications with what I call a “graph of concepts”.

Each concept is defined by parent concepts, which are depending on less concepts than their children. For example, the velocity and the derivation theory are the parents of the acceleration.
We can also note that there are two kinds of concepts: those which are located in the physical world, and those which are located in the mathematical world.

The mathematical world is a wonderful land where each concept is perfectly defined by its parents, without any approximation or ambiguity. What an amazing world it is !
However, you probably noted that the phrase “each concept has a definition which is based on parent concepts” is recursive… That means that we have a problem: if any concept needs other concepts to be correctly defined, we will need an infinity of concepts, which is not very useful. Fortunately, the mathematical world does not have this problem. In reality, the entire mathematical results are based on seven little suppositions: the Peano axioms. They are the base of the sets theory, which is the base of groups theory, which is…. etc.

That means that in the mathematical world, we can calculate the exact value of something, not only an approximation. The physical world is the world of measurability, and the mathematical world is the world of computability.
Thus, if we want to measure cognitive complexity, we must define its concepts graph, and try to enter in the mathematical world with as precise as possible physical concepts. When we will cross the border between the physical world and the mathematical world, we will be saved: we will be able to write beautiful formulas which will make exact calculations, in the aim to measure the concrete objects which are on the other side of the border.
The Cognitive Complexity’s graph of concepts
Let’s try to construct a graph of concepts for cognitive complexity. The definition above was : “The cognitive complexity of a code snippet is the time required by a mean developer to understand it”. As we can see, cognitive complexity has 4 parent concepts : code snippet, time, mean developer and understand.
Let’s try to find its grand-parents. What is a code snippet ? Do we want to measure the cognitive complexity of any code snippet, or only the valid ones ?
Assume that we are interested only by the valid code snippets. That means that the parent of the concept cognitive complexity is not code snippet, but valid code snippet. The concept code snippet is a parent of valid code snippet.
Now, we should define what means “valid” and what means “code snippet”. For “code snippet”, we should specify its formal language. So, the concept of code snippet is a child of “formal language”, which is a child of “formal grammar”, “alphabet”, “syntactic rules”, etc. Ultimately, we will find… the sets theory and the Peano axioms ! After all, an alphabet is simply a set of characters, and syntactic rules are operations on this set…
More difficult: what is the graph of concepts of the word “understand” ? That’s a much more serious problem than to define what is a code snippet. An initial approach involves remembering why we are so interested by the cognitive complexity: its strong correlation with the software maintainability (and, at the end, its cost). These two concepts, maintainability and cognitive complexity, are also linked to some actions in the real world: refactoring and debugging. Consequently, if we want our concept of cognitive complexity to have some interest in the real world, it should give us some information about the difficulty to read the code, refactor it or fix its bugs. All these notions are underlying concepts of the word “understand”, and we must specify them to be able to know what to measure.
We will not talk in this article about all of these concepts, but let’s try to define something which seems to be simple: a bug. What is a bug ? Easy ? Not at all. Of course, a bad crash of the app is a bug. But when a button is red but should be blue, it is a bug too… Why is it a bug ? Because the behavior of the system is not the same as the developer thought. It is a bug because a ticket will be opened asking the developer to fix it. Finally, this kind of bug is correlated to the cognitive complexity, because if the code is difficult to understand, the developer will need a long time to find the bug and to fix it.
You will find below a graph of concepts of cognitive complexity. This is only a draft, a graph which is a very simplified representation of the concepts underlying the cognitive complexity.
It goes without saying that this graph is not usable in its current state. All the concepts behind the different nodes must be explained, and the relations between them are still uncertain. Each node has underlying concepts which are not displayed here, and which should be exposed clearly. In reality, this graph has only one goal: organize ideas, rely concepts together, and clarify what should be clarified.
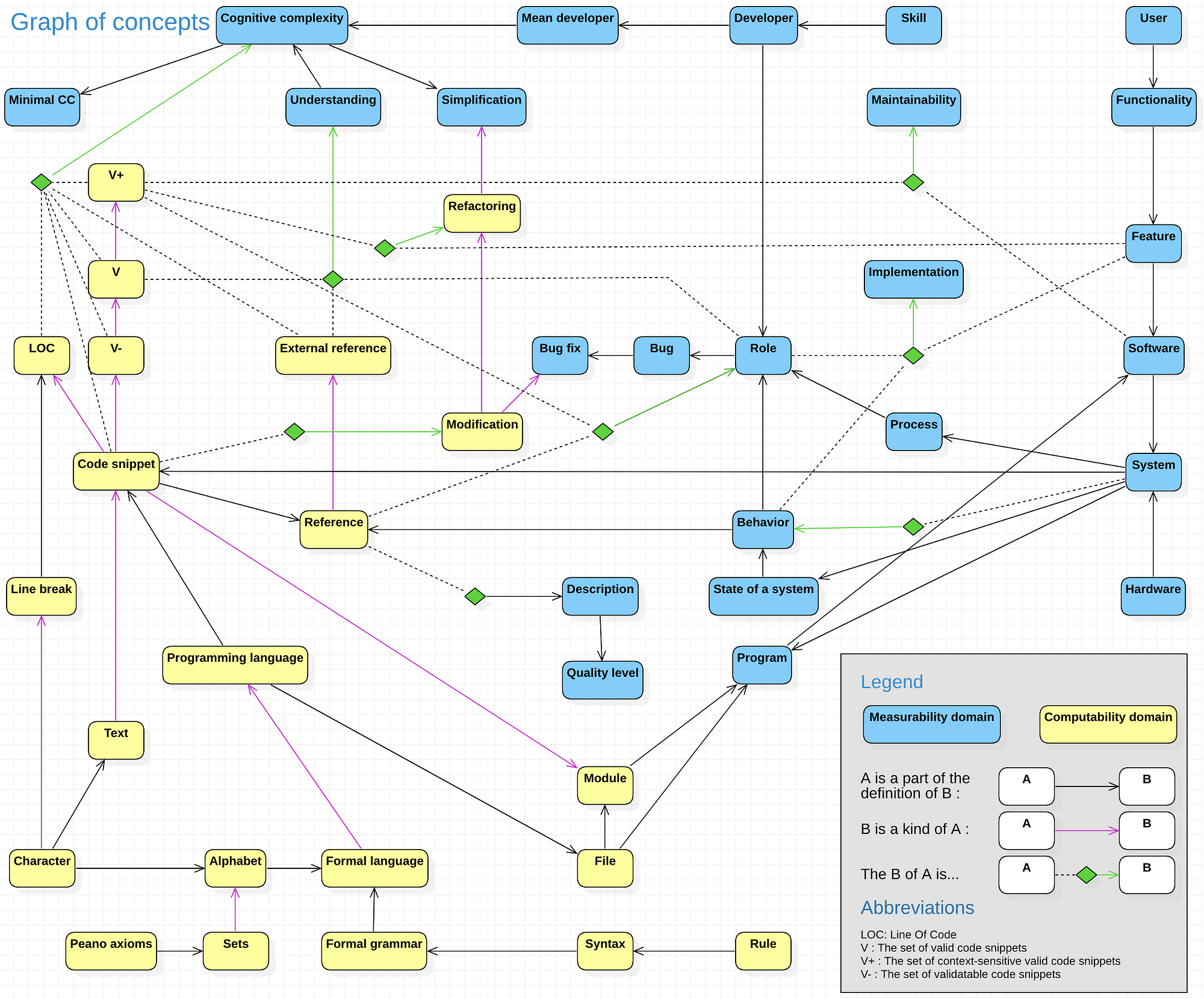
In fact, it is not very important to understand this graph or not. The most important, in my opinion, is the methodology to use to reveal the underlying concepts of cognitive complexity. With the graph of concepts methodology, we can more easily define precise concepts which will be measurable in the real world. I think that our role is to reveal the simpler concepts which are hidden behind each node of the graph of concepts.
It’s what I do during the long winter evenings…
You will find on my Github project the definitions of each concept of this graph and a lot of others. For the elements which are in the mathematical world (the yellow nodes), I began to write some demonstrable propositions. For the concepts located in the real world (in blue), I only made conjectures, because we have no results provided by real experiments.
This project is still a work in progress, a huge draft which is changing every day. Any contribution to this work will be welcome !

